Artificial intelligence (AI) is rapidly changing the world around us. From self-driving cars to medical diagnosis, AI is being used to automate tasks and make our lives easier. Data annotation plays a crucial role in enabling AI models to learn and comprehend the desired information by training them on large amounts of labeled data.
Appropriate labeling not only improves accuracy but also boosts the efficiency of ML models, ensuring they are trained with clear instructions and well-tagged datasets.
This blog is a comprehensive guide that covers everything from the basics of data annotation to the latest trends in the field.
Types of Data Annotation
Data comes in many different forms, such as text, images, and videos. Further, each of these data types requires a different type of annotation. Here are some common types.
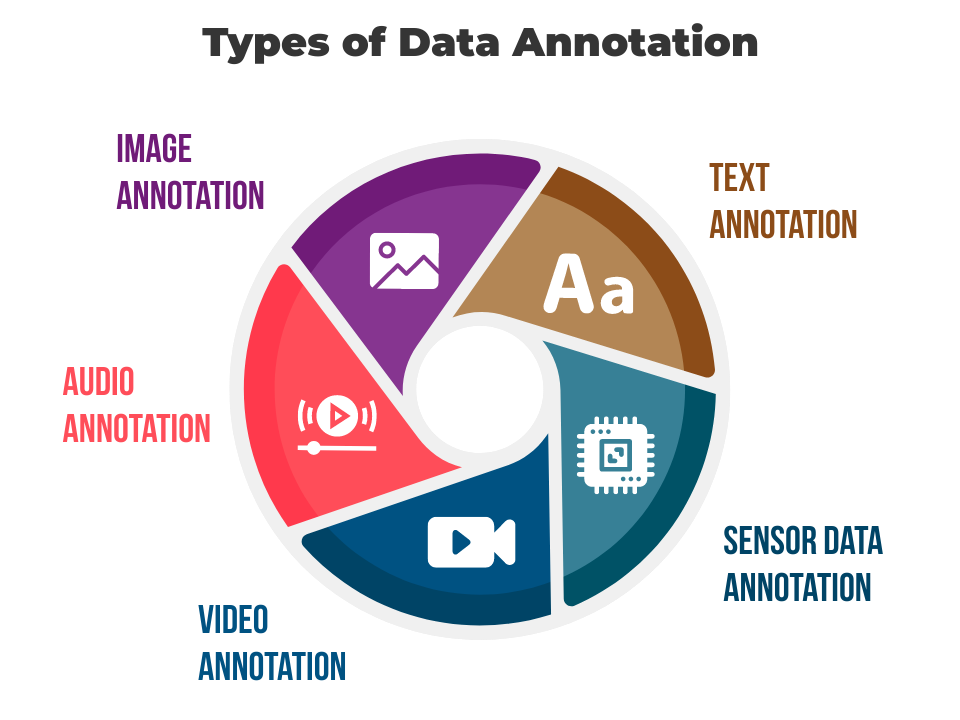
1. Image Annotation
It is the process of labeling or marking specific objects or features within an image, providing a human-level understanding of the target characteristics. The annotated data is used to train machine learning models, which aim to achieve the desired level of accuracy based on the quality of the labeled data. Some common image annotation techniques include bounding box (drawing rectangles around objects), polygon (outlining and segmenting asymmetrical shapes in images), key point (labeling specific points), and semantic segmentation (assigning a label to each pixel in an image).
2. Text Annotation
Text annotation is the process of adding tags to text data to highlight specific criteria, such as keywords, phrases, or sentences. In certain applications, text annotation can also include tagging various sentiments in text. It can include named entity recognition (identifying and classifying named entities like names, organizations, and locations), part-of-speech tagging (assigning grammatical tags to words), sentiment analysis (labeling text with positive, negative, or neutral sentiment), or text classification (assigning predefined categories to text).
3. Audio Annotation
Audio data annotation involves labeling or transcribing audio recording files. It can include speech recognition (converting spoken words into written text), speaker identification (identifying different speakers in a conversation), or emotion analysis (identifying emotions expressed in the audio).
4. Video Annotation
Video annotation involves labeling or tagging objects, actions, or events within a video. It can include object tracking (following objects as they move through the video), activity recognition (labeling actions or activities), or event detection (identifying specific events or occurrences in the video).
5. Sensor Data Annotation
This involves annotating data collected from sensors, such as accelerometers, GPS, or biomedical sensors. It can include labeling activities or behaviors captured by the sensors, annotating location or movement data, or labeling specific patterns or events in the sensor data.
Challenges in Data Annotation
Data annotation is essential for training machine learning models, but it is also important to be aware of the challenges and biases that can occur during the process. Here are some of the main challenges that can arise in the process.
1. Subjectivity and Ambiguity
Data annotation often involves subjective decisions, especially when dealing with complex or ambiguous data. Annotators may consciously or unconsciously bring their own biases into the annotation process. These biases can stem from cultural, social, or personal beliefs, leading to skewed annotations.
2. Lack of Standardization
Without clear guidelines and standards, annotators may have different understandings of the task. This can lead to inconsistent results and unreliable outcomes.
3. Poor Data Quality
The quality of the data available for annotation can greatly impact the effectiveness of the process. Subpar data quality can lead to the creation of poor training datasets, resulting in inaccurately or inconsistently performing machine learning models.
4. Time and Cost Constraints
The sheer volume of data requiring annotation, as well as the need for precision, can appear to be a grave challenge, especially for businesses lacking the necessary tools, resources, and human capacity for manual annotation.
5. Data Security/Data Breaches
Another challenge of data annotation is security. Sensitive information, such as PII or financial data, may need to be annotated. If this information is not properly secured, it could be exposed to unauthorized access, which could lead to a data breach.
Best Practices to Mitigate Data Annotation Challenges
There below-mentioned best practices can be followed to address the challenges of data annotation.
1. Clear and Concise Annotation Schema
The annotation schema is a document that defines the different types of labels that can be applied to data, as well as the rules for applying those labels. A well-defined annotation schema will make it clear to annotators what is being asked of them, and it will help to ensure that the annotated data is consistent and accurate.
2. Annotator Training
Training annotators on potential biases, emphasizing the importance of impartiality and consistency, is essential. Creating awareness of potential pitfalls and encouraging critical thinking during the annotation process can mitigate bias.
3. Regular Quality Checks
Conducting frequent quality checks on annotated data is necessary to identify and rectify errors or biases. Feedback loops and iterative improvements contribute to refining the annotation process over time.
4. Diverse Annotation Team
Assembling a diverse team of annotators helps minimize individual biases. Including members from different backgrounds and perspectives mitigates the impact of specific biases.
5. Careful Dataset Selection
Being mindful of data sources and sampling strategies helps minimize sampling biases. Ensuring that the dataset represents the target population or distribution as closely as possible is important.
Top 5 Data Annotation Tools
Data annotation is becoming increasingly important as businesses and organizations look to harness the power of machine learning. There are a variety of popular data annotation tools available for image, text, audio, and video annotation.
Here are some of the top data annotation platforms and tools.
1. LabelBox
LabelBox is a widely used data annotation platform that supports multiple data types, including images, text, and videos. It offers a user-friendly interface and a range of annotation tools.
2. Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth is a fully managed data labeling service by Amazon Web Services (AWS). It provides a platform to annotate data for machine learning tasks with the help of human labelers or automated workflows.
3. SuperAnnotate
SuperAnnotate is a collaborative data annotation platform designed for computer vision tasks. It offers a variety of annotation tools, project management features, and integration with popular machine learning frameworks.
4. RectLabel
RectLabel is a popular image annotation tool specifically designed for object detection tasks. It provides an easy-to-use interface and supports various annotation formats, including bounding boxes and segmentation masks. This functions as an offline tool.
5. LabelImg
LabelImg is an open-source graphical image annotation tool that allows users to create bounding boxes for object detection tasks. It supports multiple annotation formats and is compatible with Windows, macOS, and Linux.
The Future of Data Annotation: What to Expect in the Coming Years
The future of data annotation looks promising as the need for labeled data keeps on increasing. Here are some of the trends expected to influence the market of data annotation in the coming years.
1. Automation and AI
To increase efficiency and reduce human effort, there is a growing trend toward using automation and AI-assisted techniques for data annotation. This involves developing algorithms and tools that can automatically annotate data or assist human annotators in the process. Techniques like active learning and semi-supervised learning are used to optimize annotation efforts.
2. Domain-specific Annotation Tools
As data annotation becomes more specialized across different domains, we can expect the development of domain-specific annotation tools.
These tools will be tailored to the unique requirements and characteristics of specific industries or applications, enabling more efficient and accurate annotation.
3. The Increased Use of Synthetic Data
The use of synthetic data is increasing because it can be used to train machine learning models on data that is not available in the real world. It can also help to protect data privacy and security.
As a result, the use of synthetic data is increasing in a number of industries, including automotive, financial, and healthcare.
4. Federated Learning
Federated learning is gaining traction as a trend in data annotation due to its potential to address privacy concerns and enable collaborative annotation processes. It allows multiple entities or organizations to collectively contribute to the annotation process without sharing sensitive data.
With the increasing volume and complexity of data, federated learning allows annotation tasks to be performed in parallel across multiple devices or servers, accelerating the annotation process and improving efficiency.
5. Multimodal and Complex Data Annotation
As AI applications expand to incorporate multimodal learning, which involves modeling the combination of different modalities of data, annotation techniques will need to adapt accordingly. This includes effectively annotating and labeling data that combines text with imaging data, for example, to meet the challenges posed by complex multimodal datasets.
The future of data annotation will be shaped by advances in automation, AI, and the specific requirements of different domains. However, these trends also present challenges, such as the need for specialized tools.
Moreover, the accuracy of annotation is essential for the success of machine learning models. This is why it is important to employ experts who have deep knowledge of the various annotation techniques.
As a result, when you do not have an in-house team of annotators, outsourcing data annotation to a third-party service provider may be a more efficient and cost-effective solution.
Benefits of Outsourcing Data Annotation
Outsourcing data annotation can offer many noteworthy benefits, such as:
1. Cost-effectiveness
Outsourcing data annotation services can be more cost-effective compared to hiring and training an in-house team. By leveraging the expertise of external service providers, you can avoid the costs associated with recruitment, training, maintaining infrastructure, and ongoing employee expenses.
2. Scalability
Outsourcing allows you to quickly scale your annotation operations based on your project requirements. Service providers often have access to a large pool of annotators who can handle high volumes of data annotation, ensuring faster turnaround times. Similarly, when necessary, you can downsize your annotation operations by reducing the number of allocated resources. This can be helpful if you have a short-term project or if there are changes in your annotation needs during the course of the project.
3. Expertise and Quality
Data annotation service providers possess a diverse pool of professionals with expertise in various domains and techniques relevant to annotation. This expertise ensures high-quality annotations, which are crucial for the accurate training of machine learning models.
4. Focus on Core Competencies
Outsourcing data annotation frees up your internal resources to focus on your core business activities. Instead of allocating time and effort to annotation tasks, you can concentrate on developing and improving your products and services.
5. Access to Annotation Tools and Infrastructure
Data annotation service providers typically have access to advanced annotation tools and infrastructure, which may include annotation platforms, labeling guidelines, quality control mechanisms, and secure data handling processes. Leveraging these resources can streamline the annotation process and enhance overall productivity.
6. Improved Compliance
When you outsource data annotation, you are partnering with a third-party vendor who is responsible for protecting your data. The vendor will have the procedures in place to protect your data, such as encryption, access controls, and physical security measures. This can help you to reduce your risk of data breaches and safeguard the privacy of both your organization and your clients.
Factors to Consider When Outsourcing Data Annotation
If you are considering outsourcing data annotation, there are a few things you should keep in mind:
1. Data Privacy and Security
When outsourcing data annotation, you must ensure that appropriate data privacy and security measures are undertaken by the service provider. This involves signing confidentiality agreements, verifying the provider’s data handling practices, and ensuring that the provider complies with relevant regulations and standards, such as GDPR or HIPAA.
2. Expertise and Experience
It is important to ask about the service provider’s track record and experience with relevant projects. This can give you a good indication of their expertise and ability to deliver the high-quality annotations that you need.
3. Communication and Collaboration
Effective communication and collaboration with the annotation service provider are crucial to ensure a clear understanding of annotation requirements, guidelines, and project timelines. Regular communication channels should be established to address any questions, provide feedback, and resolve potential issues.
4. Cost
Evaluate the pricing structure offered by the outsourcing service provider. Consider factors such as per-hour rates, per-annotation unit pricing, or other pricing models. It is important to strike a balance between cost-effectiveness and the quality of the annotations provided.
5. Quality Control
When outsourcing, it is important to ensure that the service provider has a
robust quality control process in place. This process should include steps to monitor and maintain annotation accuracy, such as establishing clear quality metrics, conducting regular audits, and providing feedback to annotators. By implementing a rigorous quality control process, the service provider can help to ensure that the annotations are accurate and of high quality.
Final Thoughts
Data annotation is a critical aspect of developing robust and accurate machine-learning models. By embracing effective strategies, businesses can stay ahead in the rapidly evolving world of artificial intelligence. The process of labeling and annotating data provides the necessary foundation for AI systems to understand and learn from complex information.
By following the best practices in this guide, businesses can use data annotation to create training datasets for computer vision models, which are essential for a wide range of innovative applications.
Additionally, businesses may also want to consider outsourcing their needs. This can be a cost-effective option, while also freeing up internal resources to focus on other priorities.